
CanDIG has spent the last two years hypothesizing, prototyping, and validating data federation approaches for its national efforts. For us, data federation means something fairly specific:
- We are interested in federating queries and analyses across the network. These are read-only operations; thus we’re not worried about consistency of updates which is a complex problem in distributed read/write databases.
- In CanDIG’s case, the different sites representing different geographical regions and the data subjects are research project participants, with all of their data located at one given site. This is the case of horizontal partitioning of data. We are not linking multiple data sources for the same data subject across multiple sites; this vertical partitioning (e.g. clinical data in one store, genomic data in a second store) does happen within a site but not across sites, and we refer to crossing those divides internally for a single data subject as data integration rather than federation.
Here we describe five design dimensions - which interact but are useful to think about separately - across which decisions have to be made when designing federated queries: authentication, authorization, query flow, combining of results, and access to federation audit trails and logs. Design choices along each of those dimensions are both informed by, and help clarify, the foundational design issue: the trust model and accountability of the federated access.
Foundation: Trust Model and Accountability
The underlying constraint on making data available for querying and analyses across participating institutions, sites, or projects is the trust model for the federation, and thus the accountability that has to be baked in to the structure. Who trusts whom to see or do what?
- Is the user trusted to see, analyze, and handle the raw results from another site? Or even from their “home” site? If so, under what conditions, and how much? If not, are there some processed or aggregated results they can view?
- Do the peer sites trust each other to see and handle their raw results? Or even their queries?
- Does the researcher trust the other institutions to see, faithfully execute, and honestly return results from, their queries?
In an environment where no one trusts anyone to see or do anything, data federation isn’t meaningfully possible. On the other hand, if everyone implicitly trusts everyone to see and do everything, then data federation is barely necessary; researchers can readily gather everything they need, maybe with a little bit of tooling help or technical support.
Most situations where federation is being considered are necessarily somewhere in between. In low-trust environments, there may be some third party which is trusted somewhat more, and technologies like secure multi-party computation for querying, homomorphic encryption for combining results, and block-chains for low-trust audit logs can help; but the amount and resultant utility of data sharing is always going to be quite limited. In higher-trust environments, both a wider range of options and higher utility of data sharing are available, but audit logs and data access agreements take on new importance to ensure that the everyone is being held accountable to the higher levels of trust that have been extended to them; “trust but verify”.
In CanDIGs case, the participating sites are currently large institutions that are very well known to each other and which frequently participate in multi-institutional projects; with end users who are researchers, and typically part of groups that have long history of collaborations across the participating sites. The data is consented research data, generally collected as part of explicitly national projects, with directly identifying information (names, medical record numbers, etc) removed. This represents a comparatively high-trust use case, although as the project expands to include a larger number of smaller organizations it’s possible that this may change over time.
Dimension 1: Authentication
The technological implementation of authentication in a data federation can be quite complicated, but from a policy and overall design point of view, AuthN and for that matter AuthZ are comparatively straightforward - or at least are the least subtle.
Ultimately the choices here for authentication - for issuing accounts and tying them to individuals - are some combination of:
- Decentralized and case-by-case: each participating institution issues credentials on their own site to individual users from other institutions after some vetting procedure
- Decentralized and institution-by-institution: each participating institution recognizes the accounts of users at other institutions, by technology, policy, or both. Proposed GA4GH Passports are one way of passing those credentials around and having them recognized.
- Centralized: There is a central registry of data users of the federation project; users log in to the central registry and then make requests.
(Not listed here is authentication by institution: external “service accounts” for requests from institution B to query institution A. This is one of the few places where we are inclined to be prescriptive: if the end users in your model are individual users such as researchers or clinicians, accounts must be issued to those specific individuals, who are then accountable for their queries. Obscuring the source of the queries through institutional service accounts reduces accountability and ultimately erodes trust.)
The centralized approach can work well, particularly in a low-trust environment if there is some way to set up a central registry of users that is more trusted by each institution than their peers; but if such a central authentication registry doesn’t already exist, it has the downside of requiring one to be created and maintained, and the issue of who decides which users get added and when they are removed remains.
Decentralized and case-by-case, with (e.g.) institution A granting accounts to specific users from institution B upon request and vetting is labour intensive but has the advantage of being extremely explicit; at any given time institution A has a list of exactly which users are permitted to authenticate into their system. It does require additional process development though of how external accounts are to be renewed and/or revoked, which will likely still require some coordination between institutions.
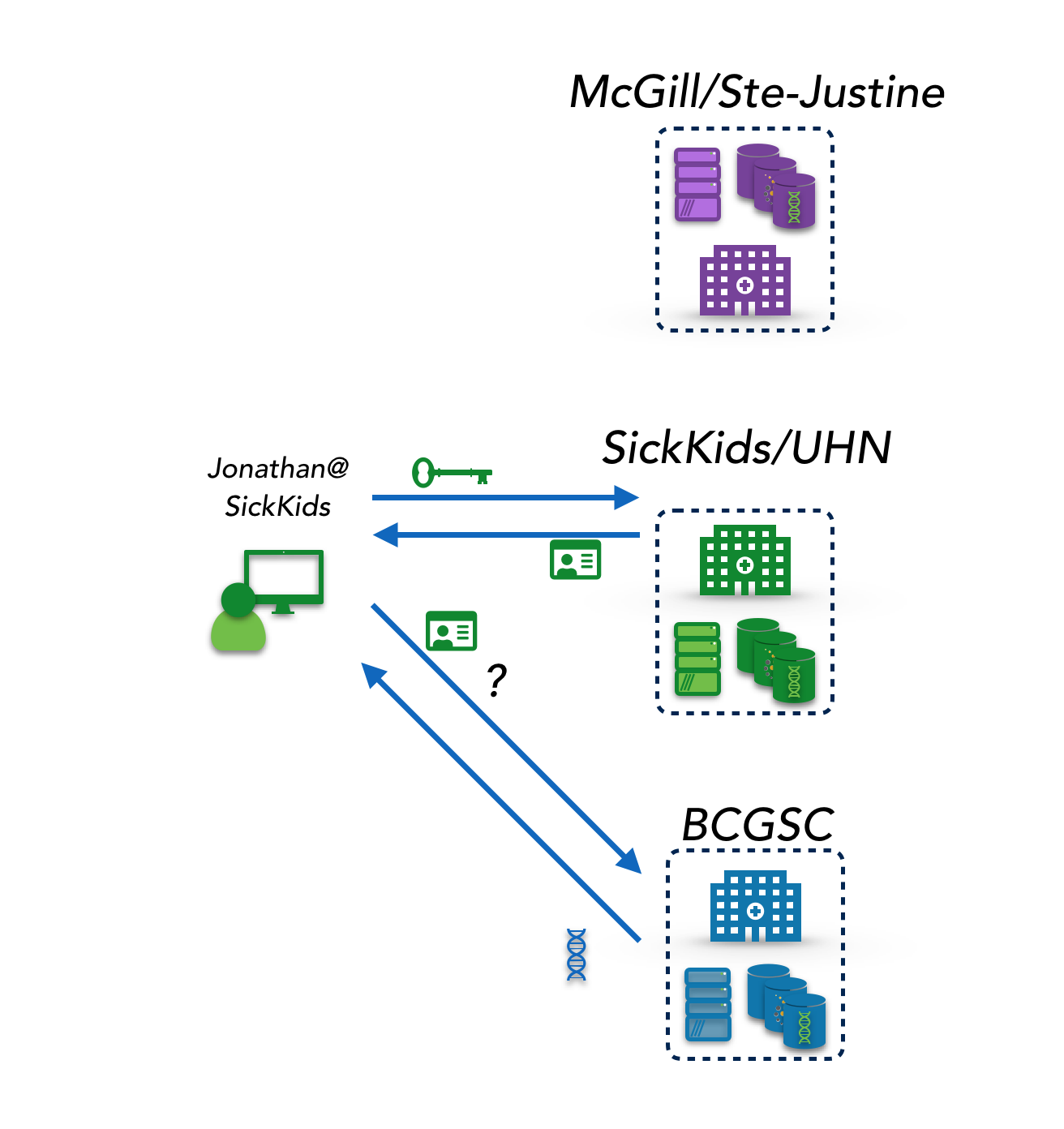
Decentralized and by-institution makes use of the existing credentials at each site, which are accepted as authentication by the peer sites (but not necessarily authorized to see or do anything in particular). While this relies on trusting the other sites to authenticate properly and to maintain good security practices around their authentication (for instance, good identity proofing, revoking accounts quickly once a user leaves the institution or project, adequate security controls), in the highly regulated areas where data federation is most needed (health data, financial data) these requirements are almost automatically met. This is the approach taken by CanDIG (Fig 1) where CanDIG users (not all or even particularly many people at the institution, necessarily) at each institution use their institutional credentials locally to get an OpenID Connect token that is used for authentication purposes at all peer sites.
Dimension 2: Authorization
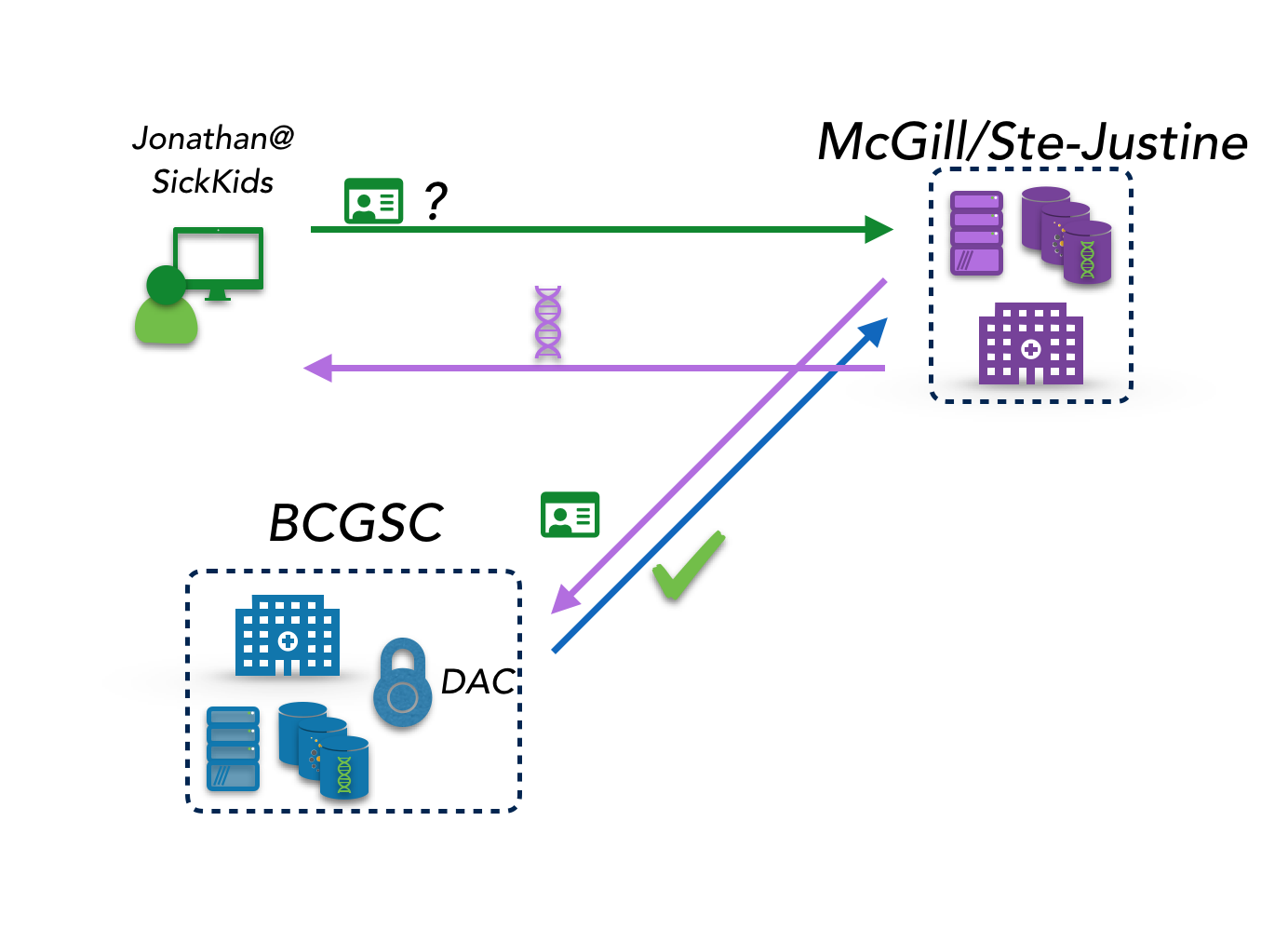
Related but different is authorization - determining which users, regardless of how they were authenticated, are allowed to make queries or perform analyses at each data site. This too can be decentralized or centralized, although in most data federations we are aware of, participating sites are (understandably) quite reluctant to outsource authorization decisions to a third party, and authorization decisions are ultimately made locally. This is certainly the model within CanDIG.
However, it is often the case that the locally-made authorization decisions are informed by additional, external information - some list of who is participating in the federation project or some subset of it - and that list can be held centrally or in a decentralized fashion.
If there is already a central authentication list, such information is most naturally held there (explicitly or implicitly - it may be the case that anyone on the central user list is implicitly authorized to make certain queries.) Alternately, in a high-trust environment that information could be maintained by each of the sites for their users (again, implicitly or explicitly).
CanDIG has a quite distributed authorization model. Much of the data supported by the CanDIG platform is part of multiple national projects, whose use is each governed by data access committees; so the sites must take that into account when making authorization decisions. Currently those lists are transmitted to the sites “out of band”, and lookups are local; we are moving to a more streamlined model where data access committee portals provide that information at query time based on the identity of the requestor.
Related to what data a user is authorized to see is a question of how much. Data sets that a user does not have row-level authorization for might still be queryable for aggregated results or for computations such as training models on. In CanDIG, we have been building out infrastructure since the beginning of the project to authorize differentially-private aggregations to data to allow data custodians to make some data sets accessible for calculations without necessarily exposing the data directly to researchers.
Dimension 3: Query Flow
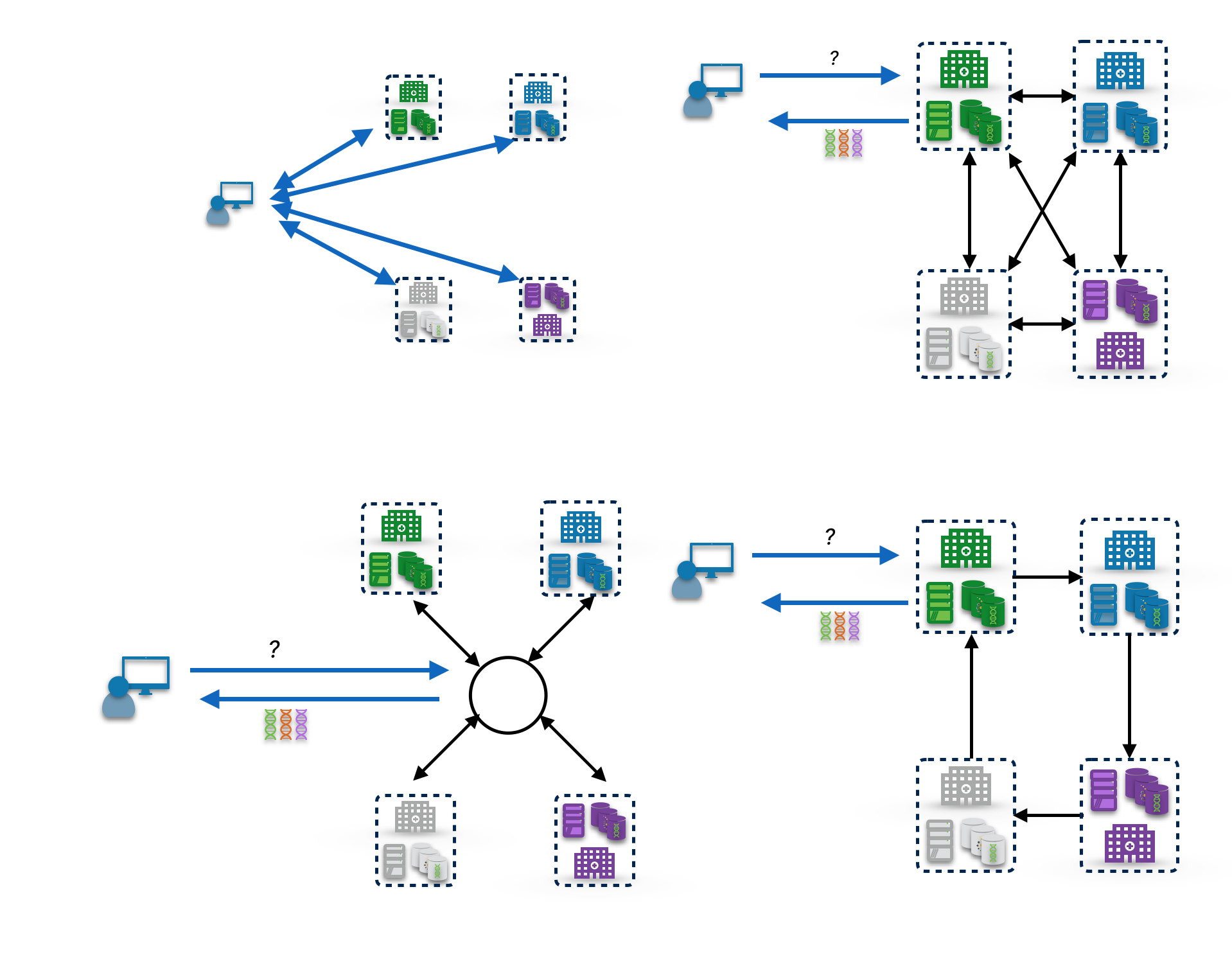
Once the request can be authenticated and a process is in place for authorizing the request, the next design question is how data - and in particular the initial query - should be communicated between the user to the participating sites.
There are four primary approaches to distributing the query:
- Client-side: the user’s client farms out the query to each site and gathers the results. This is simple and probably the most feasible approach if the authentication is performed by giving the user separate accounts at each site. It also places no requirement on trust between the sites for “seeing” their results. However, it does squander some opportunities to privately and efficiently combine results on the way back.
- Peer-to-peer - tree or mesh: In this model, the initial site being requested (typically the user’s “home” site) is the one to farm the request out to some or all peer sites, which then perform the query and may again farm it out to additional sites. For a small number of sites, the possible topologies of the peer network is limited enough that the pattern doesn’t matter, and this becomes a “distributed-hub-and-spoke” model where each site is a hub. This requires sites to see some of each others results, but allows some privacy- and efficiency-enhancing early combining of the results.
- Peer-to-peer - cycles: Here again the communication is between peer sites, but the query visits each site in sequence and gathers intermediate results, and is sent back to the researcher when the query and result returns to the initial site. This allows each site to see the combination of previous partial results, but it also allows some obfuscation of those results without affecting utility (for instance, in a “count the number of results” aggregation, the first site can add a large random number, and remove it at the end, so that for N > 2 no site knows how many results any other site contributed). The lack of parallelism in combining results however means there are built in limits to the scalability of this approach, depending on query complexity and latency tolerance.
- Hub-and-spoke: This is the model that most people first think of when they imagine data federations; one portal that all users communicate with which then farms out queries to all of the other sites. There certainly are situations when this approach makes sense - if there’s already centralized infrastructure (for authentication and authorization) then it’s a natural approach, but then you have a single point of failure for security; and in a low trust environment this doesn’t require any of the peer sites to see any results from the other sites (but it does require a trusted third party to aggregate the results). In any situation it is a single point of failure for availability (which admittedly isn’t typically a major problem for these sorts of efforts, especially in low-trust environments) and requires the construction of some central infrastructure if none already exists. On the other hand, if the multiple participating sites don’t quite have the same data access APIs, this one central portal provides a single, simple place to place the “adapters” necessary to connect the sites.
In the CanDIG model, which is committed for a variety of reasons to avoid any centralized infrastructure, we take the peer-to-peer approach; with currently three and soon five-or-six sites the topology is largely irrelevant, but we’d like to move towards more of a mesh model. In early days we did experiment with the cycles model which worked well enough for our needs but was slightly more complicated and we didn’t need the advantages of obscuration of partial results (which we’ll talk about more in the next section).
Dimension 4: Getting and Combining Results From Sites
After the authenticated, authorized query successfully reaches sites, the results have to be generated and aggregated.
How that can be done comes down to some different questions to our trust model:
- Does the query itself need to be obscured from the data site, or are there issues of trust with the data site faithfully executing the query? In that case some of the features of secure two-party computation may be useful.
- Do the partial results from each site have to be hidden from other sites where aggregation must occur? In that case, sending results directly back to the researcher (explicitly, or implicitly by only sending two-party encrypted cryptotexts back) may help. Alternately the results can be aggregated in transit at the peer sites using homomorphic encryption to aggregate quantitative results or secure multi-party computation for a few kinds of more complex computation.
- If the sites are trusted to see the partial results from the other
sites but one doesn’t want to expose which come from what sites or
preserve some level of plausible deniability about individual rows,
there are other options:
- Privacy-enhancing methods such as mentioned with the “visiting the sites in a cycle” adding and eventually removing fake data
- Local differential privacy adds noise to each result to be aggregated to provide plausible deniability to each participant’s data. Global differential privacy combines the results first and then applies differential privacy techniques.
Note that there’s something of a tradeoff here in the privacy of results; the obvious methods for avoiding having the participating sites see each other’s partial results mean that the researcher sees quite explicitly which result came from which site, which does expose some information to the researcher that isn’t strictly necessary to provide an answer to the result, and requires some work on the client side.
There is also a functionality tradeoff; the stronger privacy preserving method (secure multi-party computation and homomorphic encryption) both require carefully crafted approaches to the particular sort of query/calculation in question, and so adding a new query type or data type requires significant amounts of work, and sometimes progress on open research questions; there’s no approach that works well with arbitrary queries.
Finally, in a hub-and-spokes model of data flow, the central site may have higher/lower levels of trust with each of the participating sites than their peers. This can be exploited/must be mitigated when designing the result combination approach.
In CanDIGs case, (a) the sites trust each other strongly, (b) each user has an affiliation with a site at which the query results are gathered, and (c) authorizations are tied to institutional affiliation, suggesting the institution is at least as trusted as the user, so we currently allow the results they are authorized to see to be aggregated “in the clear” at the home site. We do make efforts to ensure through API design that as little unnecessary information is exposed as possible. In early days we experimented with homomorphic encryption for simple aggregations and may revisit such privacy-enhancing approaches to aggregation as the project grows.
Further we use local (regional?) differential privacy for sensitive data sets. Since in our model it is difficult to distinguish the trust of the institutions with those of the researchers, global differential privacy - combining the results at the users institution, then applying noise, then returning the results - hasn’t been used, even though that can result in higher result utility per unit privacy. Moreover, applying the differential privacy at each site separately allows each site to apply its own privacy policies to determine the level of differential privacy “noise”, which is a very useful capability in our very privacy-heterogenous case.
Dimension 5: Access to Audit Trails and Logging
Finally, to understand access patterns across the federation it is useful to have the capacity to access audit logs across the federation rather than simply having a single local window of logging available. In CanDIG, data custodians of data sets that are distributed across sites want to be able to see at a national level how and by whom the data entrusted to them is being used; site operators want to be able to see global access patterns for the purposes of intrusion/suspicious behaviour detection; and federation operators will find such information useful for capacity and capability planning.
The difficulty here comes from the fact that unless carefully handled, system logs are arguably more sensitive than the health data, since if too much data is exposed they could compromise the security of one or more system and thus jeopardize the security and privacy of significant amounts of the health data.
As with authentication and authorization, the choice is along a spectrum of centralized to decentralized.
- Centralized: these approaches have the great advantage of simplicity, and are a good fit if one has authentication and/or authorization handled centrally, and/or a central hub for queries. A central query hub can naturally perform the query and response logging, and participating sites can send any additional information that the federation judges as required either as part of the response or out-of-band from the query.
- Distributed: Here, the audit logs remain separate at the participating site, and either manual procedures or technical tools must be used to get global views of access patterns.
In CanDIG, our operations teams work together quite closely, and so distributed logs plus rapid communication between staff at the sites serve as our main audit log model. As data volumes and numbers of sites increase, this is unlikely to remain feasible. Since each CanDIG site is running the same software stack, we can collaboratively determine what is safe to put into logs, and we would like to move towards a model where the logs are just another distributed data set can be queried, but this remains some time in the future.
Summary
We’ve presented here the CanDIG model of data federation, in the context of five useful dimensions for considering how to design other data federations:
- authentication
- authorization
- query flow
- getting and combining results from and between sites
- access to federation audit trails and logs
Design decisions along each of those dimensions both stem from and help clarify the underlying trust model of the data federation - how much sites trust each other, how much data they are willing to let each other see, and the trust and authorization relationships between the users and the sites. Working through possibilities along these dimensions is a useful way to design, plan for, or even just assess the feasibility of a data federation project.